I’m off to the RMA study day on “Embodied Research Methods in Music& Sound” in Liverpool on Tues 18th May. … More
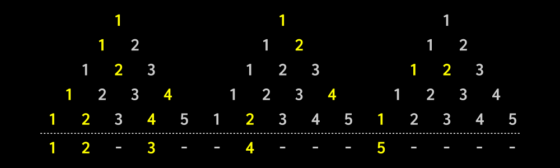
Making music with text[ure]
I’m off to the RMA study day on “Embodied Research Methods in Music& Sound” in Liverpool on Tues 18th May. … More

This was a fun chat with Mylar Melodies for his Why We Bleep podcast, about algorave, tidalcycles/strudel, live coding and … More

I’ve been a bit behind on blogging in general, but made five posts in the Algorithmic Pattern blog yesterday.. On … More

I was unsure about writing this blog post, but today I was turned away from signing up for the openly-advertised … More
I’m happy to have a talk accepted for the first groove workshop happening in Jan 2023, “an online meeting seeking … More
Kate Sicchio and I had a nice chat about our interest in patterns as part of this year’s International Conference … More
I’m fascinated with this video: At the start Sylvie Rasch shows a sock that she says is completely done by … More
We had some pandemic-related challenges, but Eimear + I had a great time collaborating as part of a residency for … More
I’m really looking forward to joining JB from Music Hackspace to go through the pre-history, history, present and potential future … More

I’ve been enjoying the idea of “research products” as opposed to “research prototypes”. Prototypes are understood as a partially working … More